Lightfeed Extract Now Open Source
We're excited to announce that we've open-sourced lightfeed/extractor — our LLM-powered web data extraction library that's been successfully processing over 10 million records in production.
Along with this milestone, we are also excited to introduce several new features to the Lightfeed platform that enable you to monitor value changes, extract with greater accuracy and receive timely notifications.
Open Sourcing Lightfeed Extract
While working with LLMs for structured web data extraction, we encountered challenges with invalid JSON and broken links in the output. This led us to build a robust library focused on reliable extraction and enrichment with features like:
- Clean HTML conversion: transforms HTML into LLM-friendly markdown with main content extraction
- LLM structured output: leverages latest LLMslike Gemini 2.5 flash to balance accuracy and cost
- JSON sanitization: recovers and fixes imperfect LLM outputs to match your schema
- URL validation: automatically handles relative URLs, removes invalid ones, and repairs markdown-escaped links
GitHub: github.com/lightfeed/extractor
// Example usage
import { extract, ContentFormat } from "@lightfeed/extractor";
import { z } from "zod";
// Define your schema. We will run one more sanitization process to
// recover imperfect, failed, or partial LLM outputs into this schema
const schema = z.object({
title: z.string(),
author: z.string().optional(),
tags: z.array(z.string()),
// URLs get validated automatically
links: z.array(z.string().url()),
summary: z
.string()
.describe("A brief summary of the article content within 500 characters"),
});
// Run the extraction
const result = await extract({
content: htmlString,
format: ContentFormat.HTML,
schema,
sourceUrl: "https://example.com/article",
googleApiKey: "your-google-gemini-api-key",
});
console.log(result.data);
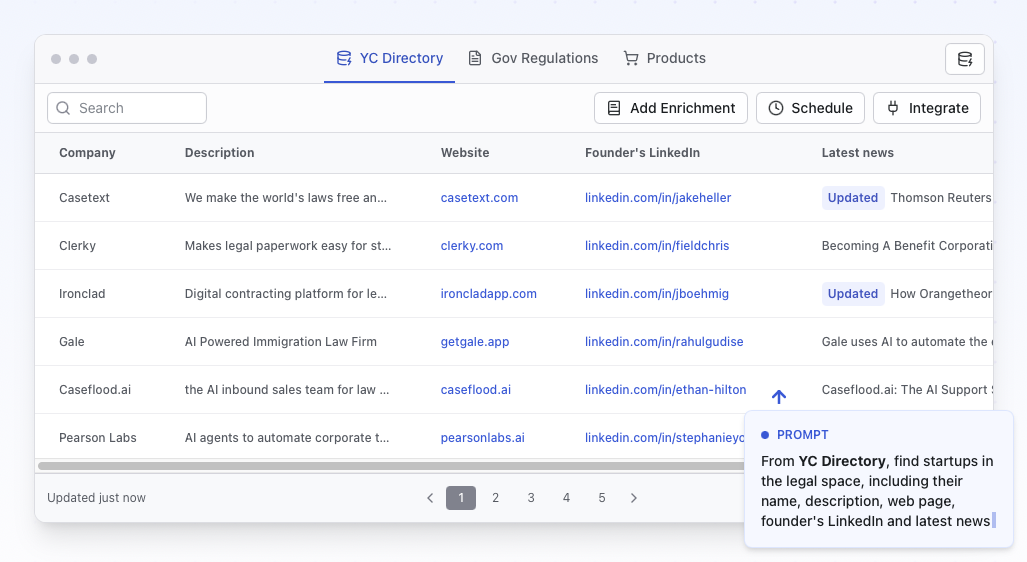
Value History Tracking
Our new Value History Tracking feature makes it easy to spot changes in your data at a glance. When viewing extraction results in tables or lists, any field that's been updated is automatically highlighted with visual indicators showing both the current value and what it changed from.
This is particularly useful for monitoring price fluctuations, inventory changes, or any time-sensitive data.
![]()
List Mode vs Detail Mode
When adding a website to Lightfeed, you can now specify whether you're extracting a list of items or a single detailed item. This simple choice guides our AI to produce more accurate results by providing clear context to the LLM about the extraction job.
List Mode optimizes extraction for pages containing multiple similar items (like product listings, search results, or directories), helping maintain consistent structure across all entries and preventing the LLM from getting distracted by unrelated page elements.
Detail Mode is designed for pages focused on a single item (such as product pages, company profiles, or articles), instructing the LLM to capture comprehensive information including nested details and relationships that might be missed otherwise.
By selecting the appropriate mode for your target page, you'll achieve more accurate extractions without writing custom logic, as the LLM receives precise guidance about what to look for and how to structure the output.
Learn more about List Mode and Detail Mode in our documentation →
Email Notifications
You can now choose to receive extraction results directly in your inbox with three flexible options:
- Receive only new items that appear for the first time
- Get both new and changed items
- Receive the complete dataset of each extraction run
This makes it simple to monitor exactly what matters to you — whether you're tracking new listings, want to know when prices change, or need a complete record of each extraction.
Learn more about Email Notifications in our documentation →
Join Our Community
We're excited to see how you'll use Lightfeed in your projects, so don't hesitate to reach out!
- Join our Discord community to ask questions, share your projects, and get help from the Lightfeed team and other users
- Star our GitHub repository if you find it useful